About the course
In this course, we’ll look at topics such as working with queues, differentiating processes based on the way they handle transactions, as well as clearly identifying transactions to automate within a process. Apart from this, we’ll also look at the possibility of using Orchestrator as a repository for libraries, assets, and so on.
What you will learn in this course
At the end of this course you should be able to:
- Use Orchestrators resources directly in Studio.
- Publish, install and update libraries and templates in Orchestrator.
- Store files in storage buckets and use them in automation projects.
- Create, populate and consume Orchestrator queues.
- Describe the relationship between different queue concepts and make the correct correlations.
- Identify and explain the types of processes, as well as clearly identify transactions to automate within a process.
What are Storage Buckets?
Storage buckets are Orchestrator entities used for storing files which can be used in automation projects. UiPath Studio offers a set of activities to simplify working with storage buckets. These activities are available in the UiPath.System.Activities pack, under Orchestrator.
Storage buckets can be created using the Orchestrator database or some external providers, such as Azure, Amazon, or MinIO. Each storage bucket is a folder-scoped entity, allowing fine-grained control over storage and content access.
Why do you need Storage Buckets?
UiPath Studio offers many options to work with files in automation projects. In certain contexts, storage buckets may be the best way: for example, when you need to use large files stored in a centralized location or when you need to grant access to multiple robots in a controlled way.
What are queues?
Queues are containers that can hold an unlimited number of items. Items can store multiple types of data, by default in free form. If a specific data schema is needed, it can be uploaded at queue creation in the form of a JSON file.
Queues in Orchestrator will store items and enable their distribution individually to robots for processing. They also monitor the status of the items based on process outcomes. As soon as the queue items enter processing, they become transactions. Items are meant to be indivisible units of work: a customer contract, an invoice, a complaint, and so on.
Why do you need queues?
Working with queues is very useful in large-scale automation scenarios underlined by complex logic. Such scenarios pose many challenges—bringing items from multiple sources together, processing them according to a unique logic, efficient use of resources, or reporting capabilities at individual item and queue level, including the use of SLAs.
Creating queues
Queues are easily created in Orchestrator from the entry in the menu with the same name. They are folder entities, which allow setting up fine-grained permissions.
When creating a queue, you set the maximum number of retries (the number of times you want a queue item to be retried) and the Unique Reference field (select Yes, if you want the transaction references to be unique). You can update existing queue settings, such as:
- The queue name.
- The Auto Retry option.
- The maximum number of retries.
In Orchestrator, newly created queues are empty by default. To populate them with items you can either use the upload functionality in Orchestrator, or Studio activities. Bulk upload is supported directly in Orchestrator, from .csv files.
Populating and consuming queues
To ensure the optimal use of the robots, queues are typically used with the Dispatcher-Performer model of running automation. In this model, the two main stages of a process involving queues are separated:
- The stage in which data is taken and fed into a queue in Orchestrator, from where it can be taken and processed by the robots. This is called Dispatcher.
- The stage in which the data is processed. This is called Performer.
Working with queues and queue items is done using the specific activities from the UiPath. System.Activities official package, under Orchestrator. These are:
Add Queue Item
When encountering this activity in a workflow, the robot will send an item to the specified queue and will configure the timeframe and the other parameters.
Two of the properties that are worth highlighting are:
- Deadline—add a date until which the items must be processed.
- Priority—select Low, Normal, or High, depending on the importance of the items that are added by this activity and how fast you want them to be processed.
Add Transaction Item
The robot adds an item to the queue and starts the transaction with the status ‘In progress’. The queue item cannot be sent for processing until the robot finalizes this activity and updates the status.
Get Transaction Item
Gets an item from the queue to process it, setting the status to ‘In progress’.
Postpone Transaction Item
Adds time parameters between which a transaction must be processed.
Set Transaction Progress
Enables the creation of custom progress statuses for In Progress transactions. This can be useful for transactions that have a longer processing duration, and breaking down the workload will give valuable information.
Set Transaction Status
Changes the status of the transaction item to Failed (with an Application or Business Exception) or Successful. As a general approach, a transaction that failed due to Application Exceptions will be retried, and a transaction that failed due to Business Exceptions will not be retried.
Within any given queue the transactions are processed in a hierarchical manner, according to this order:
Items that have a Deadline, as follows:
- in order of Priority—and
- according to the set Deadline for items with the same Priority.
Items with no Deadline, in order of Priority—and
- according to the rule First In, First Out for items with the same Priority.
For example, a queue item that’s due today at 7:00 pm and has a Medium priority is processed first, before another item that has no due date and a High priority.
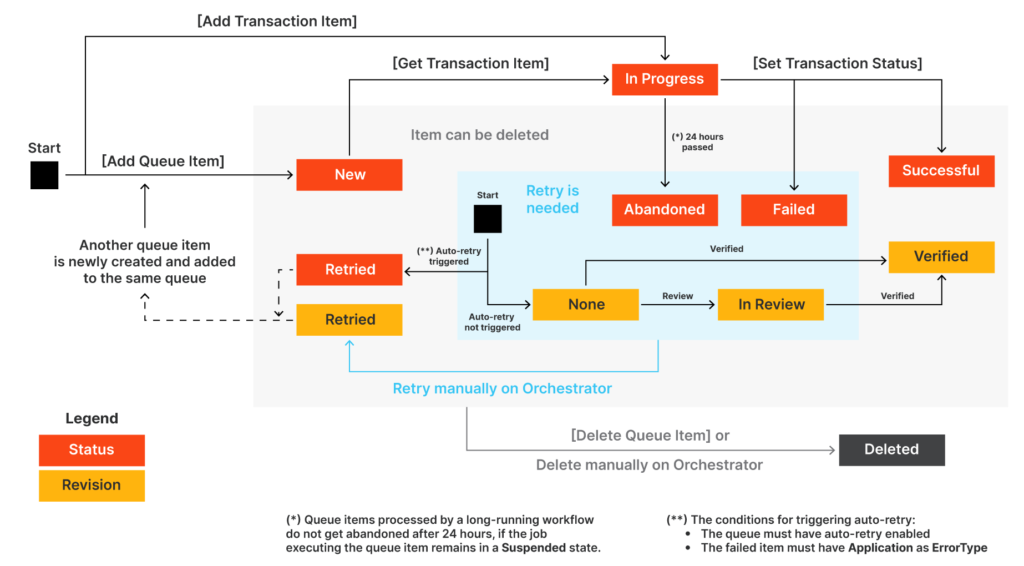
Queue item statuses
A queue item can have one of the statuses below. These will be set automatically following human user and robot actions, and/or using the Set Transaction Status activity. Custom sub-statuses can be set for queue items which are ‘In Progress’, using the Set Transaction Progress activity.
New–
- The item was just added to the queue with Add Queue Item, or
- the item was postponed, or
- a deadline was added to it, or
- the item was added after an attempt and failure of a previous queue item with auto-retry enabled.
In Progress–
The item was processed with the Get Transaction Item or the Add Transaction Item activity.
When an item has this status, the custom progress status is also displayed, in the Progress column.
Failed–
The item did not meet a business or application requirement within the project.
It was therefore sent to a Set Transaction Status activity, which changed its status to Failed
Successful–
The item was processed and sent to a Set Transaction Status activity, which changed its status to Successful.
Abandoned–
The item remained in the In Progress status for a long period of time (approx. 24 hours) without being processed.
Retried–
The item failed with an application exception and was retried (at the end of the process retried, the status will be updated to a final one – Successful or Failed.
Deleted–
The item has been manually deleted from the Transactions page.
Apart from these above, queue items which have been abandoned or failed can enter a revision phase. In such a case, there are specific revision statuses, set by the reviewers.
The Stop mechanism
Each running process in Orchestrator has a Running state associated with it. You have the option to stop or kill the process. Kill will halt the process immediately, which may cause unwanted errors. Stop allows you to create a safe closing path for the process.
After the Stop signal is sent, the process ends when it is safe to do so. This requires using the Should-Stop activity and a Stop mechanism in a workflow. It registers if the Stop button has been pressed in Orchestrator before the execution flow reaches the Should Stop activity. This is like saving a computer game before exiting as opposed to shutting down the computer.
In other words, it allows you to configure the workflow so that it performs various routines after the stop is triggered. You can, for example, perform a “clean up” routine to close windows and applications which have been targeted within the workflow.
Linear
The process steps are performed only once. If the need is to process different data, the automation needs to be executed again. For example, an email request coming in triggers an automation which gathers data and provides a reply to the sender. The process is executed for each individual email.
Linear processes are usually simple and easy to implement, but not very suitable for situations that require repetitions of steps using different data.
Iterative
The steps of the process are performed multiple times, but each time different data items are used. For example, instead of reading a single email on each execution, the automation can retrieve multiple emails and iterate through them doing the same steps.
This process implementation is done with a simple loop. But it has a disadvantage—if a problem happens while processing one item, the whole process is interrupted and the rest of the items remain unprocessed.
Transactional
Similar to iterative processes, the steps of transactional processes repeat multiple times over different data items. However, the automation design is such that each repeatable part processes independently.
These repeatable parts are then called transactions. Transactions are independent of each other because they do not share any data or have any particular order to be processed.
What is a transaction?
A transaction represents the minimum (atomic) amount of data and the necessary steps required to process the data, by fulfilling a section of a business process. A typical example would be a process that reads a single email from a mailbox and extracts data from it.
We call the data atomic because once it is processed, the assumption is that we no longer need it as we advance with the business process.
Facts
Which of the following Orchestrator entities are available through the Resources panel in Studio?
Answer:
- Processes
- Assets
- Queues
…
If a company’s Orchestrator consists of multiple tenants, will the libraries be shared between the tenants?
Answer: It depends on the configuration. From the Tenants settings menu, admins can choose between a single feed for the entire Orchestrator host or one feed for each tenant.
…
Which of the following statements is true?
Answer: Orchestrator admins can toggle between read-only and write privileges for each storage bucket.
…
By default, the data stored in a queue item is in a free format, but a specific format can be set.
…
Which of the following types of resources can be shared across folders?
Answer:
- Assets
- Queues
…
Which of the following activities is the most appropriate one to be used at the beginning of an automation project which will become a performer?
Answer: Get Transaction Item
…
What happens when a new version of an existing library is published to Orchestrator?
Answer: Both versions will be available.
…
Which of the following statements about stopping a job is true?
Answer: A job started from Orchestrator can be stopped only from Orchestrator.
…
Provisioning: Creates and maintains the connection with robots and attended users.
Inter-connectivity: Acts as the centralized point of communication for third-party solutions or applications.
Running automation jobs in unattended mode: Enables the creation and distribution of automation jobs through queues and triggers.
Control and license distribution: Creation of licenses, roles, permissions, groups, and folder hierarchies.
…
Consider a developer having access to several folders in which resources are stored, including their own personal workspace. Can they work with the resources in all the folders in Studio if they are signed in to Orchestrator?
Answer: Yes – they will see the resources in the folder selected and they are able to switch from the panel.
…
Congratulation

